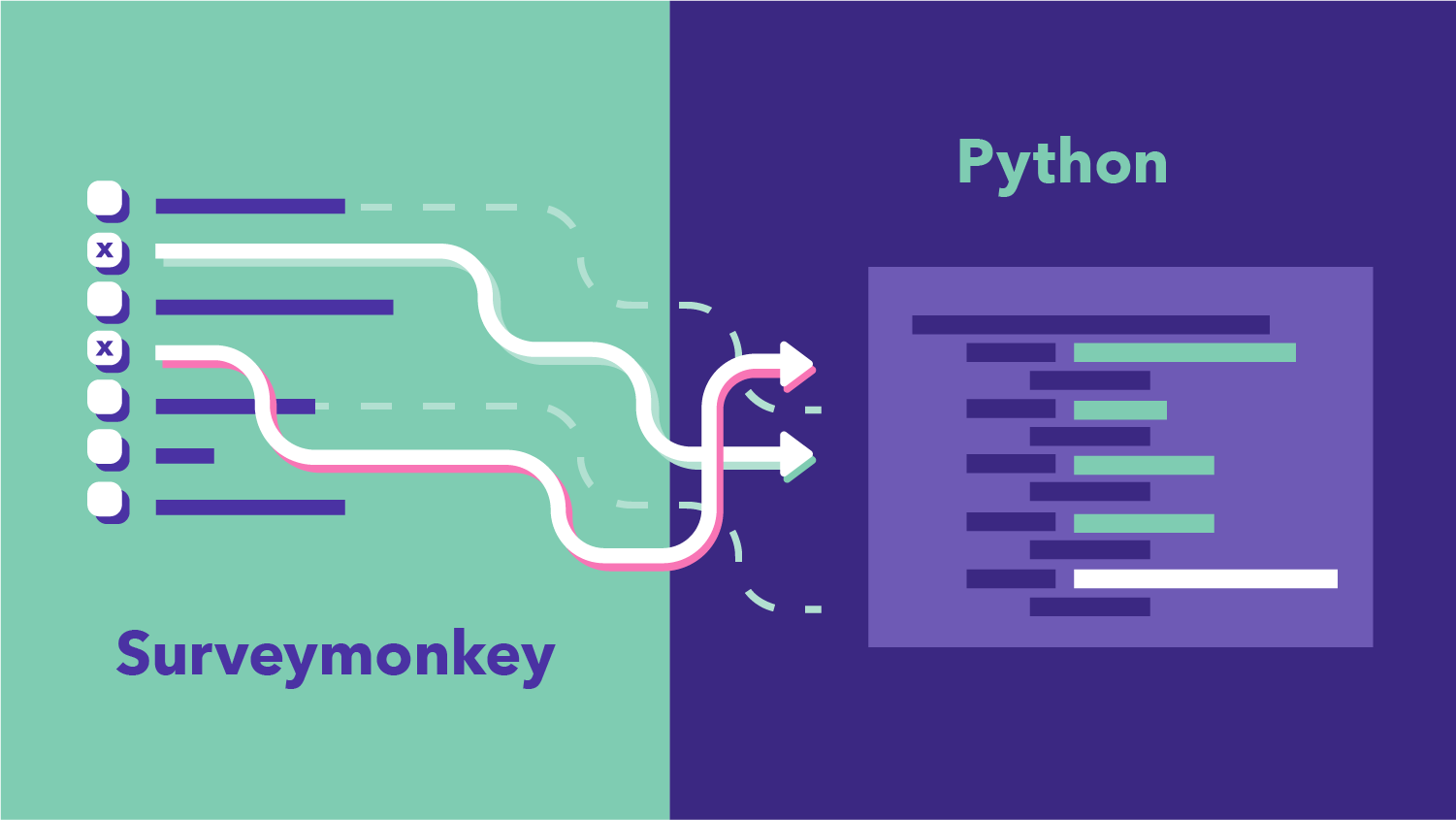
As a user researcher, it is important to know more about our users and their preferences concerning our product. One way to do that is by conducting surveys.
In order to gather user feedback from our global markets, we need to conduct a survey with a slightly different set of questions/translations for different countries, and then analyze the results and compare if there is any difference across countries concerning user needs.











Follow us on